1.After signing in, choose “ML Model” on the top navigation bar.
2.Click on “Build Model” button on the top right corner of the portal.
3.Enter the Model name and description then click “Next”.
4.Select the Model type (Image, Audio, Time Series) and click “Next”.
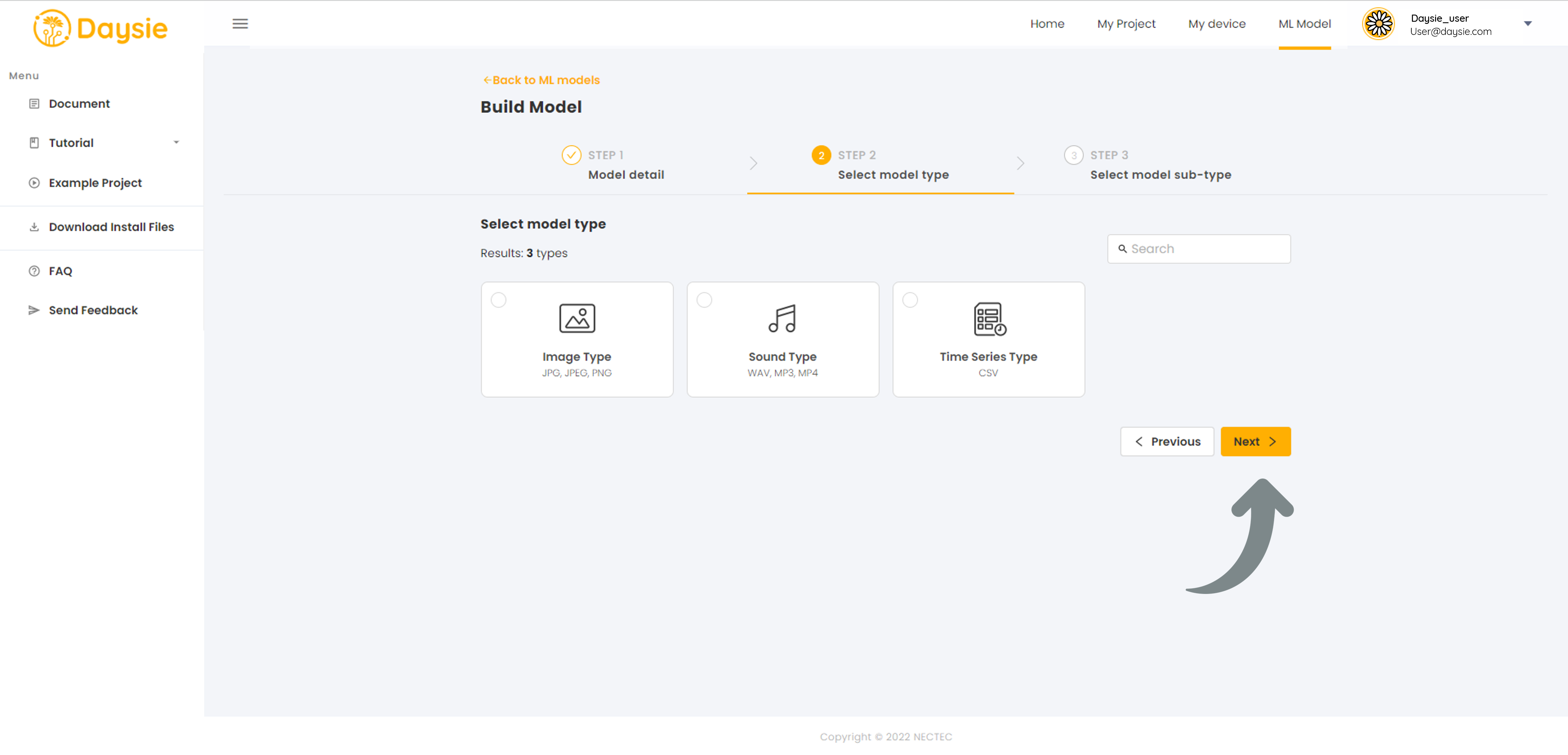
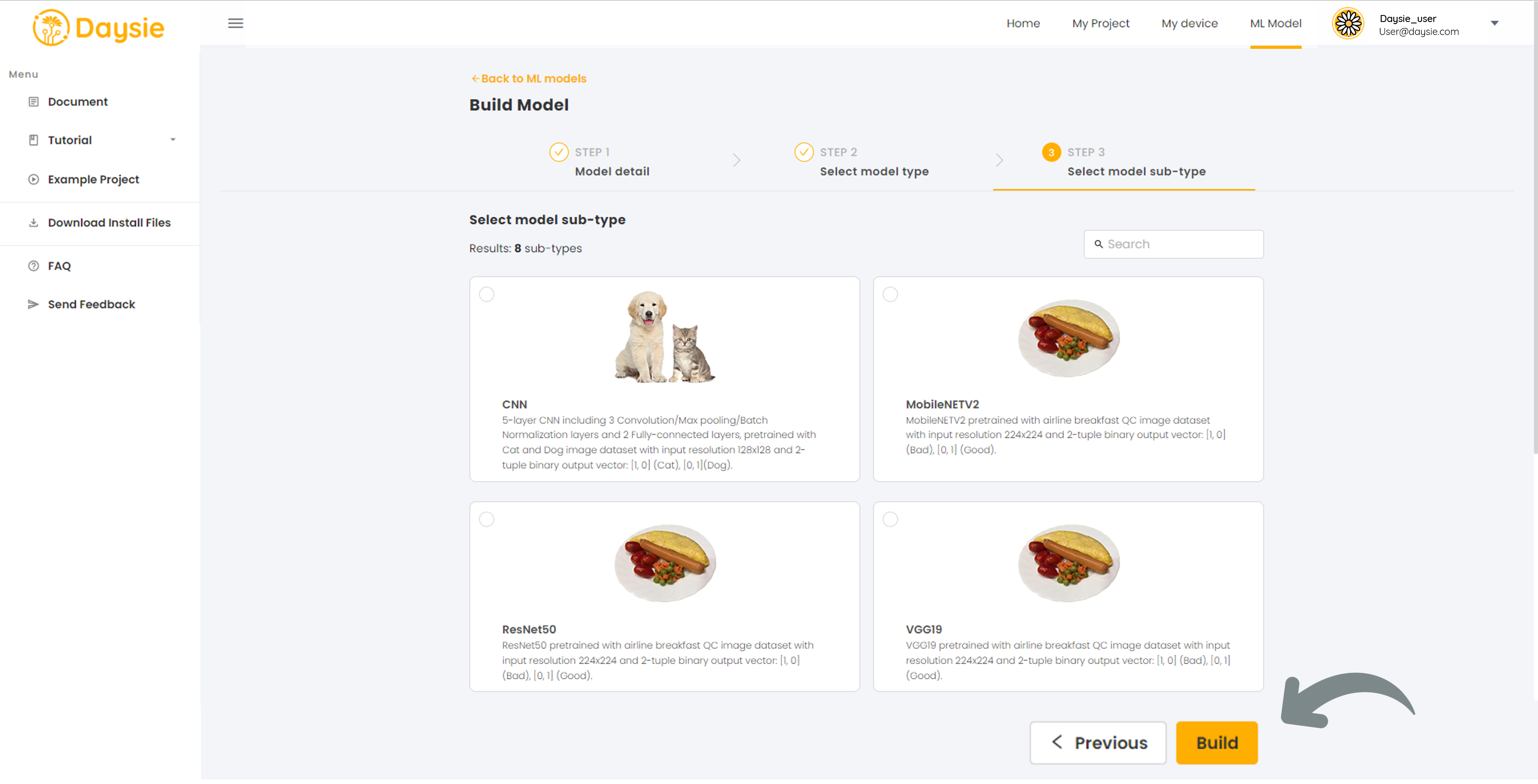
5.Select the Model sub-type that is most suitable to your data and targeting output. Click “Build” (Read how to choose Model sub-type below).
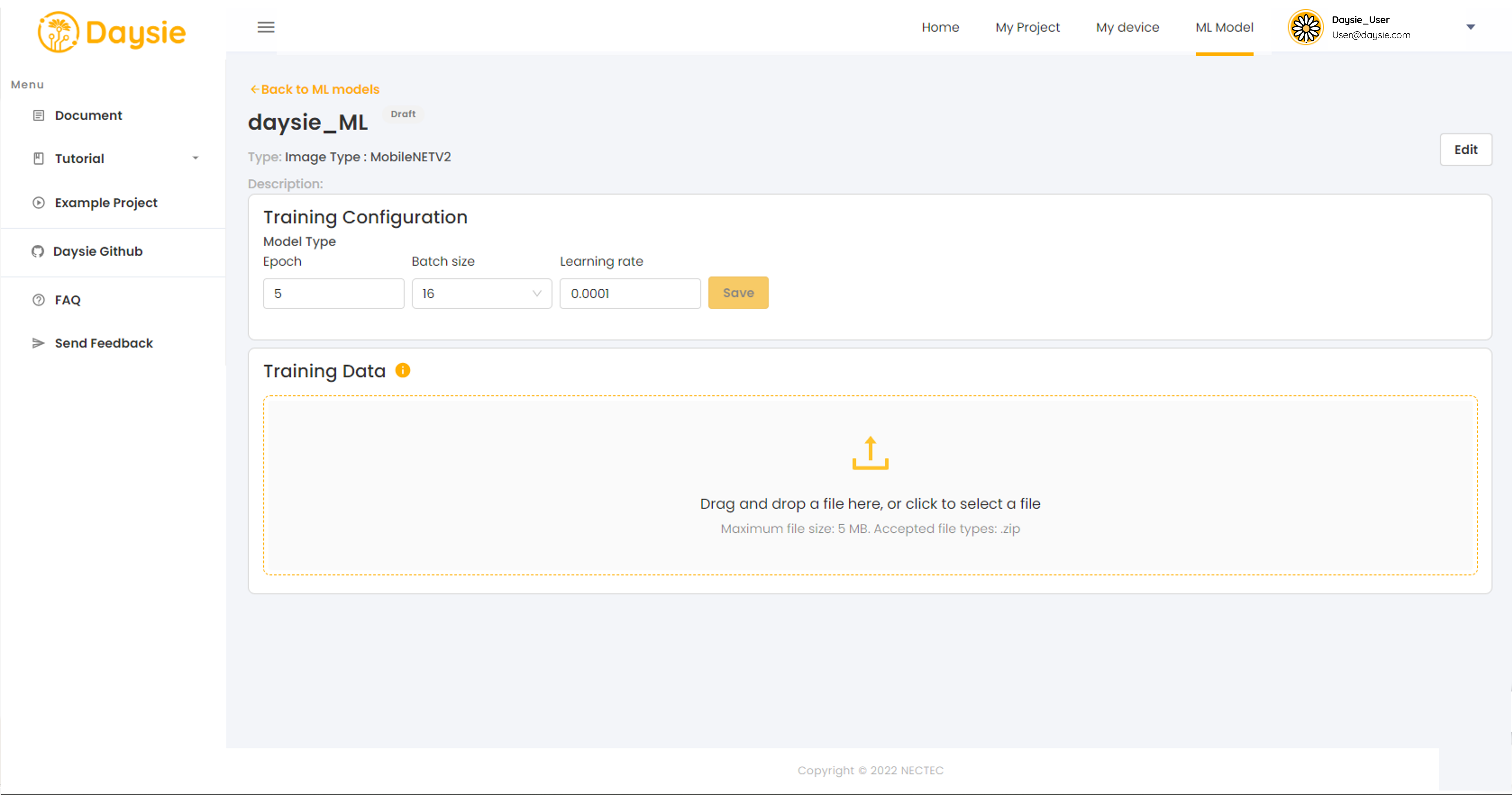
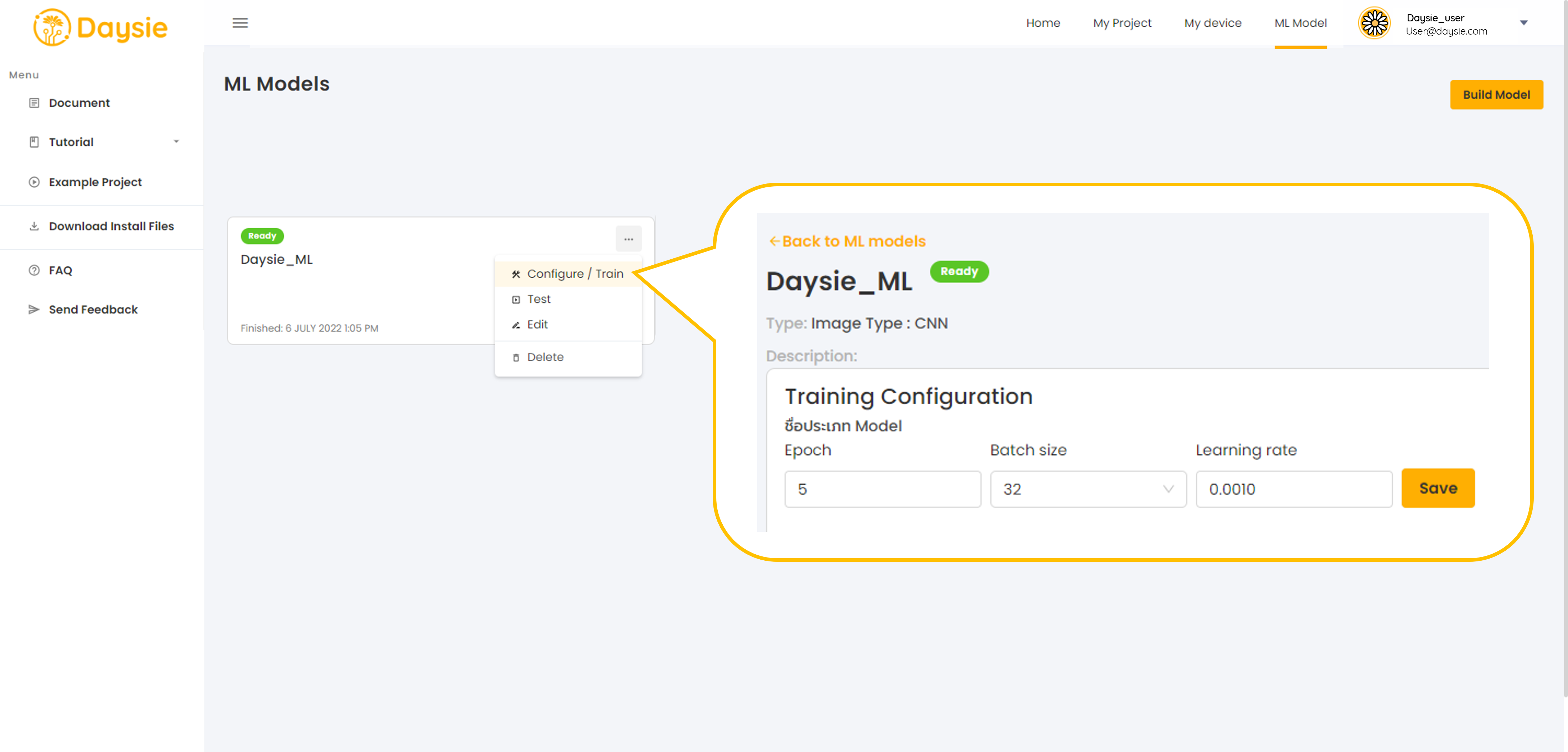
6.Set hyperparameters for ML model training, i.e., epoch, batch size, and learning rate. You may opt to keep the default values we set for each model type.
7.Import training dataset from Device.
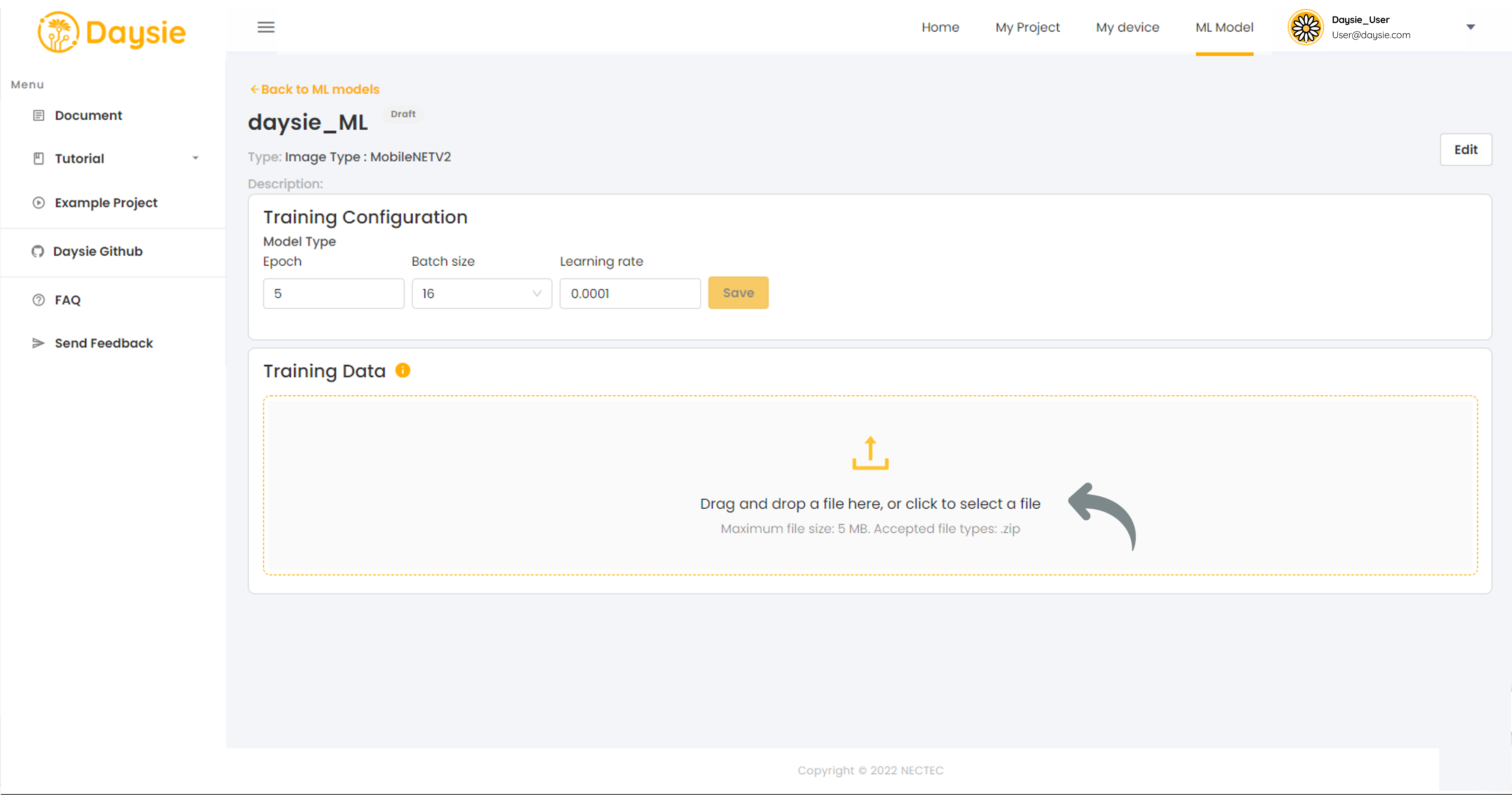
Please read and follow
Training Dataset File Preparation guide for each model sub-type carefully.
Incorrect format of file or wrong file type will result in training error.
8. Select the training dataset file to be utilized and click “LET’S TRAIN” button.
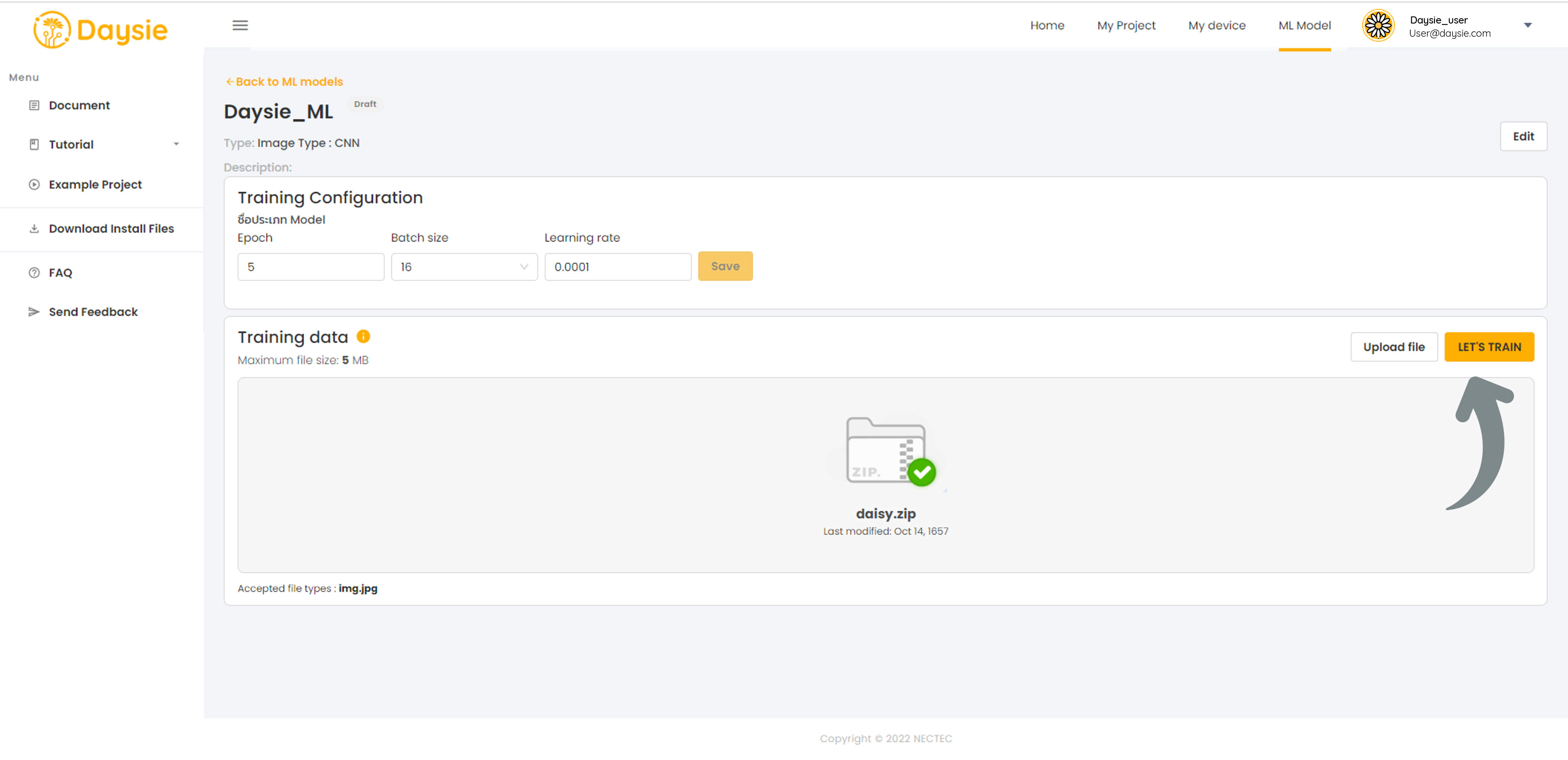
9.Model status:
- Draft: If you do not start training by clicking on “LET’S TRAIN” for any reasons, we will save your model configuration you have already chosen up to that point as a draft. You can finish the process by clicking on “Configure” command in the more options menu of the model, including uploading the dataset.
After you click “LET’S TRAIN”, these model status may appear:
- Uploading: The system is downloading your training dataset file.
- Queuing: The model is waiting in the queue to be trained.
- Training: The model is being trained.
- Ready: The model is finished training.
There are also error status, i.e.,
- Upload Failed: The system fails to download file. The error may be caused by server disconnection, too large file size, etc.
- Train Failed: The system fails to train the model. The error may be caused by incorrect file type or file format, unsuitable hyperparameter setting, etc.
10.When the model status turns “Ready”, you may test the accuracy of the model by clicking on more options icon. Select “Test” command.
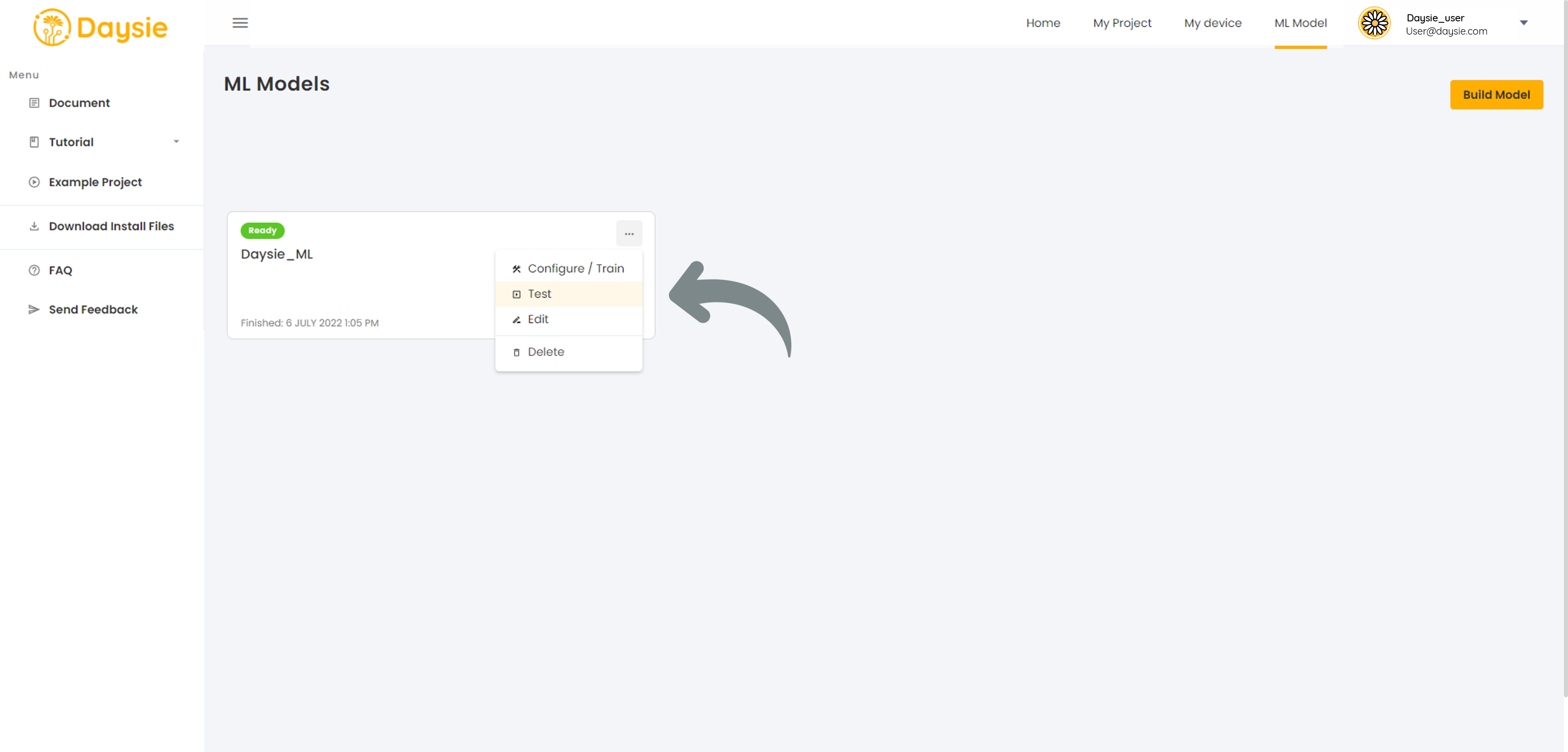
11.If the prediction results are not satisfactory, you may retrain the model by clicking “Configure” on the more options menu. Adjust the hyperparmeters in 6. or improve your dataset. Daysie has a quota for how many times you can train your model daily (read Quotas)
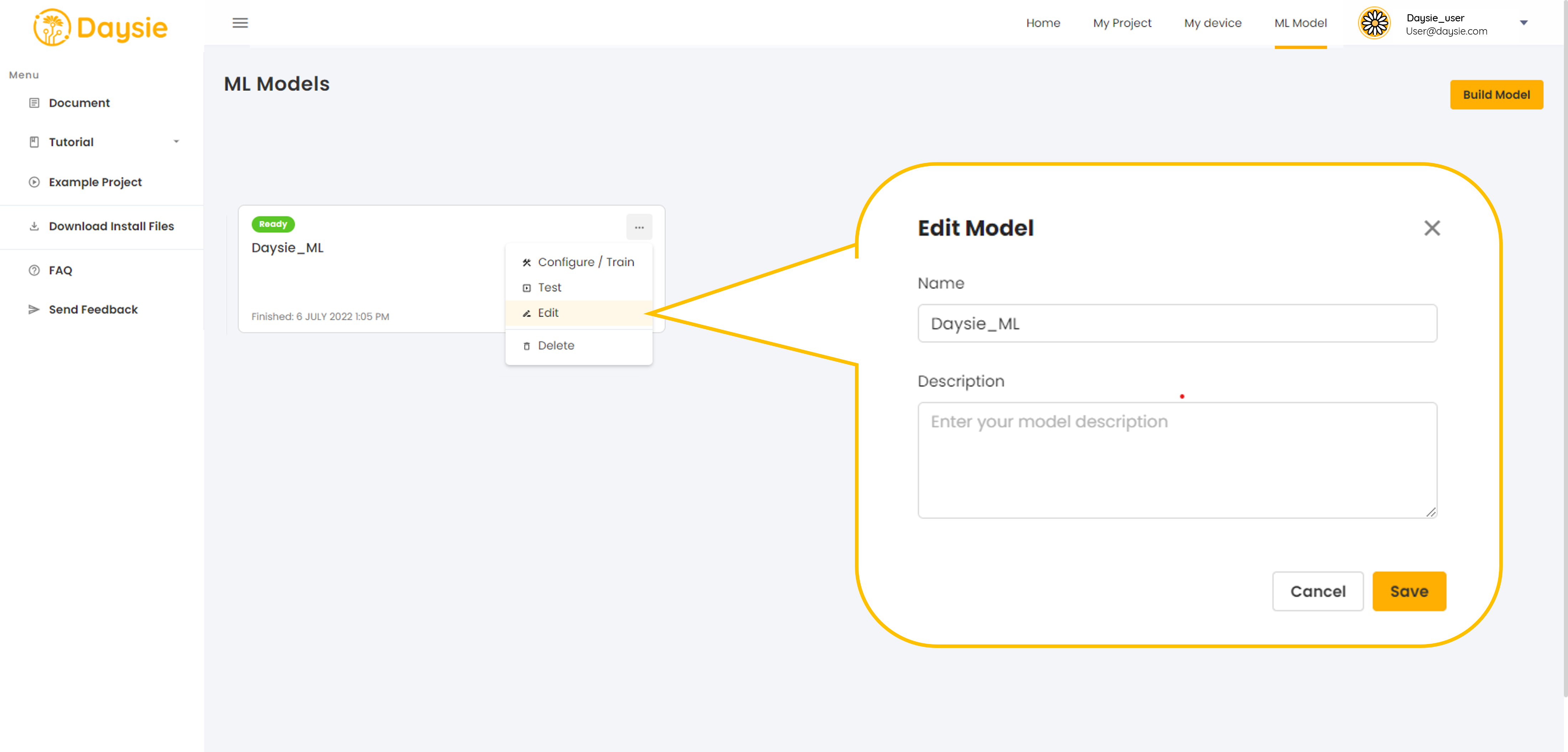
12.You can change the model name and description by choosing “Edit” in the More Options menu and click “Save”.
13.You can delete model while in any status at anytime. Click More Options icon and choose “Delete”. Click confirm to delete model.
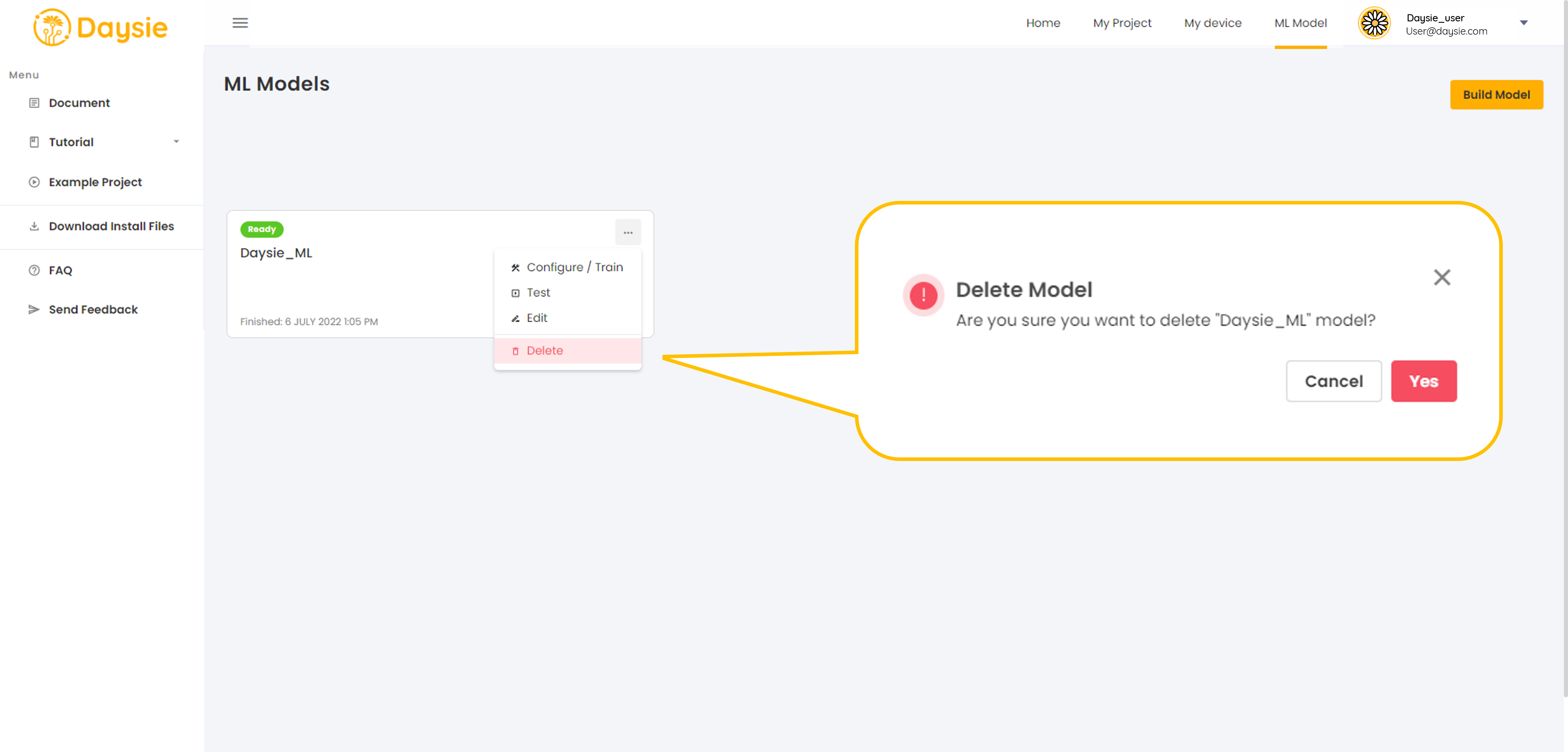
Before deleting a model, it is advisable to check whether it is not included in any recipe in use.
The model once deleted cannot be recovered and your recipe will lose the model.
How to select the model
1.Select model type according to your data type, e.g., images, audio, time series data.
Time series data consists of vector data points in (t,x1(t) ,x2(t),..,xn(t))format,where t is Unix time and xi(t) refers to input parameter value i at time t.
For example, n=2, x1 is temperature, x2 is humidity, a single data point would be (1656432776, 28.7, 65.5).
2. Select model sub-type from the degree of similarity between your training dataset and the sample data shown or described. Every model is pre-trained by our dataset, one sample of which is shown in the model sub-type description. The closer the similarity, the faster the training process.
However, as long as you choose the type correctly and your dataset is carefully cultivated and of good quality, the system shall be able to train your model successfully despite the lack of similarity.
3.Set hyperparameters as follows:
- Epoch refers to the number of rounds the whole training dataset is to be fed to train the model. ML model training is an iterative process and generally requires more than a single epoch to converge to target.
Except for special circumstances, we recommend you to start from the default setting. However, you may subsequently attempt to adjust epoch according to the size of your dataset, but should still keep it below 100 to avoid overfitting.
- Batch size refers to the size of the training data subset to be fed to train the model per one update. Most of the time the dataset is too large to be fed all at once and we need to divide it into several batches. Batch size can be as small as 1 and as large as the size of the dataset. Theoretically, large batch size will result in faster training, but can be very computationally expensive. Too large batch size can even cause overfitting. In contrast, small batch size will be more gentle to computing resources, but the model can take a long time to converge.
We recommend you use the default value for batch size, which is either 32 or 64.
- Learning rate is a very important parameter in ML model training. It determines how large the learning step for each update is. Large learning rate could mean faster training or it could lead to learning instability. Small learning rate, on the other hand, will take the model longer to train and converge. Since Daysie uses adaptive learning rate algorithm, which adjusts learning rate automatically as the training progresses, we recommend you start from the default setting first.